Abstract
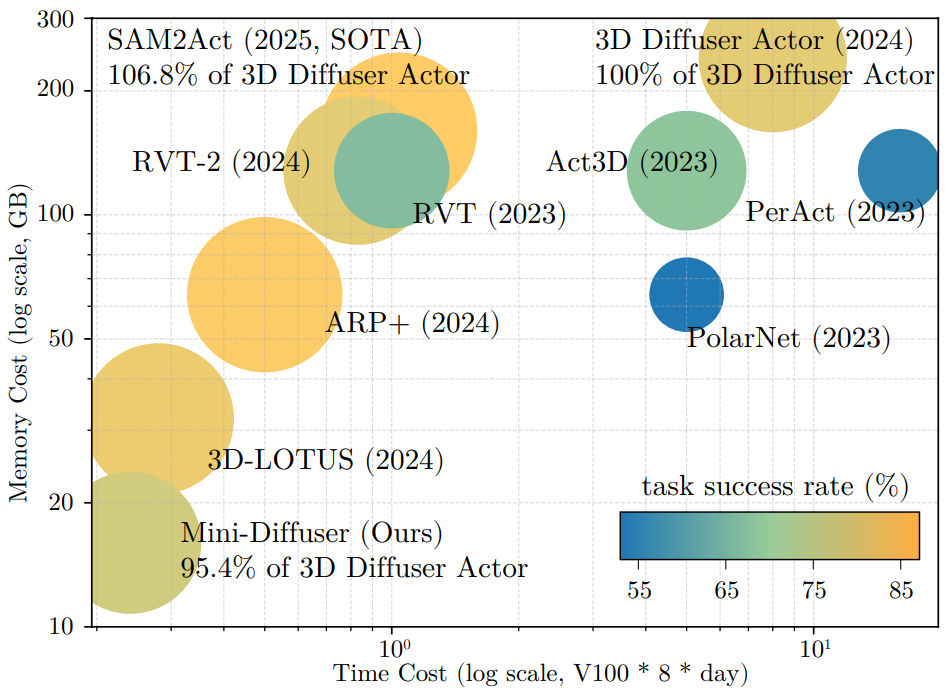
We introduce Mini-Diffuser, a method for training multi-task robot policies that can perform a variety of tasks using vision and language as input—while training significantly faster and using far less memory than previous approaches. The key insight comes from comparing how diffusion models are used in different domains. In image generation, diffusion models refine high-dimensional pixel data. In contrast, robot actions are much simpler, typically involving only 3D positions, rotations, and gripper states. However, the conditions—such as images and language instructions—remain high-dimensional. Mini-Diffuser takes advantage of this asymmetry. Instead of generating one action per input, it generates multiple action samples for the same vision-language input. This allows the model to train over 20× more efficiently with minimal extra cost. To support this strategy, we introduce lightweight architectural changes that prevent interference between samples during training. Mini-Diffuser offers a simple, fast, and effective recipe for training generalist robot policies at scale.